|
P2P file-sharing accounts for more traffic than amy other application--including the Web--on the Internet. In terms
of sheer traffic. P2P file sharing can be considered the most important Internet application. Modern P2P file-sharing
systems mont only share MP3s, but also videos, software, documents, and images. There are also many important issues
relating to security, pricacy, anonymity, copyright infringement, and intellectual property.
P2P file sharing is a compelling content distrbution paradigm because all content is transferred directly between ordinary
peers without passing through third-party servers, P2P filse sharing takes advantage of teh resources in a large collection
of peers-sometimes millions!
Although no centralized, third-party server gets involved in the file transfer, it is important to keep in mind that
P2P file sharing still relies on the client-server paradigm. The requesting peer is the client and the chosen peer is
the server. The file is sent from server peer to the client peer with a file-transfer protocol. Since any peer
can request or can be chosen, all peers must be capable of running both the client and server sides of the file transfer protocol.
Centralized Directory
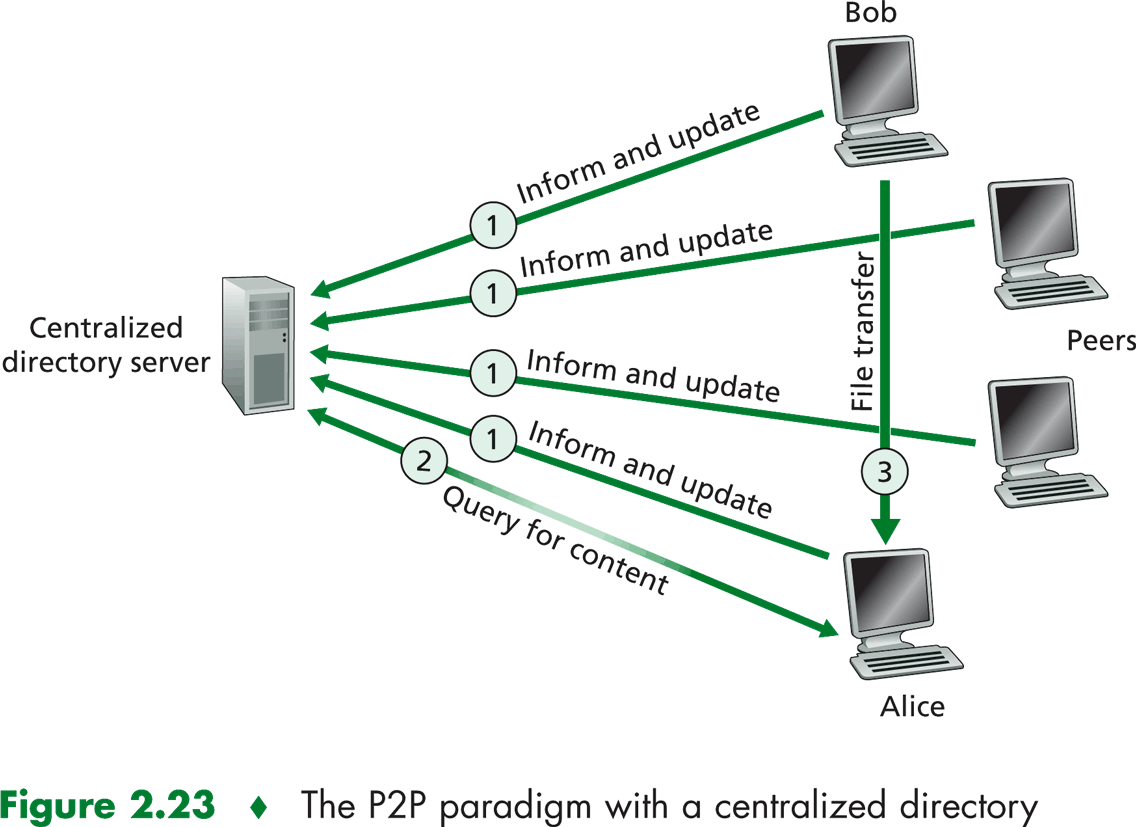
One of the more straightforward approaches to locating content is to provide a centralized directory.
The P2P file-sharing service uses a large server to provied the directory service. The application running in the peer informs
the directory server of its IP address and of the names of the objects in its local disk that it is making available for sharing.
The directory server knows which objects the peer has available to share. The directory server collects this information
from each peer that becomes active, thereby creating a centralized, dynamic databasethat maps each object, or removes an object,
it informs the directory server, so that the directory server can update its database.
In order to keep is database curent, the directory server must be able to determine when a peer becomes disconnected.
A peer can become disconnected by closing its P2P client application or simply by disconnecting from the Internet. One
way to keep trackof which peers remain connected is to send messages periodically to the peers to see it they respond.
IF the direcroty server determines that a peer is no longer connected, the directory server removes the peer's IP addresses
from the database.
P2P file sharing with centralized directory uses the huybrid client-server, P2P architecture. Using a centralized
directory for locating content is conceptually straightfoward, but it does have a number of drawbacks.
- Single point of failure. If the directory server crashes, then the entire P2P application crashes.
- Performance bottleneck. In a large P2P system, with hundreds of thousands of connected users, a centralized server
must maintain a huge database and must respond to thousands of queries per second.
- Copyright infringement. P2P file-sharing systems allow users to easily obtain copyright content for free.
The salient drawback of using a centralized directory server is that the P2P application is only partially decentralized.
The file transfer between peers is decentralized, but the process of locating content is highly centralized--a reiability
and performance concern.
Query Flooding
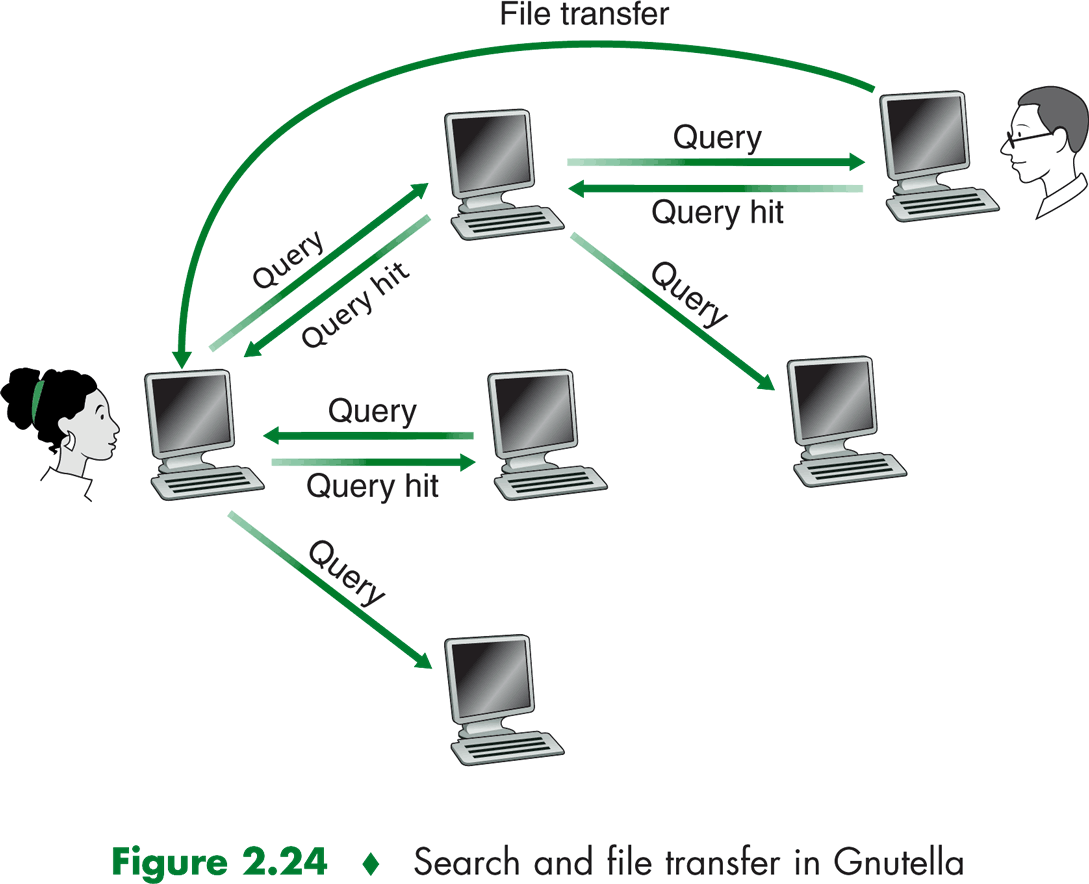
Gnutella, a public-domain file-sharing application, locates content using a fully distributed approach.
The peers form an abstract, logical network called an overlay network, which is defined in graph-theoretic terms as follows.
If peer X maintains a TCP connection with another peer Y, then we say there is an edge between X and Y. The graph consisting
of all active peers and the connecting edges defines the current Gnutella overlay network. Note that an edge is not
a physcial communication link; instead, an edge is an abstract link which may consist of ten of underlying physical links.
An edge may represent the TCP connection between a peer in Lithuania with a peer in Brazil.
Query flooding is when a peer receives a Query message, it checks to see whether the keyword matches
any of the files it is making avalable for sharing. If there is a match, it sends back a QueryHit Message, which contains
the file name and file size for the match. The QueryHit message follows the revese jpath of the Query message, therby
using preexisting TCP connections.
Although the decentralized Gnutella design is simple and elegant, it is ofetn criticized for being nonscalable.
Whith query flooding, when ever a peer initiates a query, the query propagates to every other peer in the overlay network,
dumping a significant amount of traffic into the Internet. The Gmutella designers responded to this problem by using limited
scope query flooding.
|

